On Monday June 13, I defended my capstone project in a meeting with the advisory committee and today, June 16, I submitted the final write-up for sign-off by the Graduate School.
I’m of course very excited to be at this milestone. I offer my thanks and appreciation to everyone who contributed to or supported this project in some way, and to my advisory committee for their guidance and feedback.
I’ll plan to leave this site up for the near future, and have preserved a static HTML version of it for the future in the event that I take down the live version.
Following up on previous updates (April 1, Feb 28), here’s another summary of what’s been unfolding with my capstone project work:
Progress
April was a very full month, focused almost entirely on building the first version of the tool we’d planned, delivering it to Simon and team for testing, open sourcing and publishing the software code for the tool, discussing and clarifying feedback received from Simon and team, and then refining and re-delivering.
As another side project, I also had the opportunity to create a CrowdTangle API Library in PHP, and the folks at Meta/CrowdTangle are considering it for inclusion in their documentation for CrowdTangle so it could be used by others.
Per the original project timeline, I’ll be shifting in to compiling and writing up summaries, analysis, project reviews and related discussion, as well as creating a video walkthrough or presentation, as a part of the final project deliverables.
As needed, I’ll make myself available to Simon and team for continued refinements or questions about the tool as they increase their usage of it in the daily news harvest workflow.
Problems
Carried over from last month, the Bloomfield team has had some challenges locating and contacting additional stakeholders for me to interview (at least one representative reader of the Daily Bulletin, and one person who has provided financial support to the project). Still hoping and expecting to be able to complete these conversations soon.
Since delivering the tool I’ve built to Simon and his team for testing, we’ve spent the last few weeks collecting feedback, discussing details and implications of that feedback, making refinements to the tool, and moving toward the point where it is ready for daily use. This post is a walk through of that process.
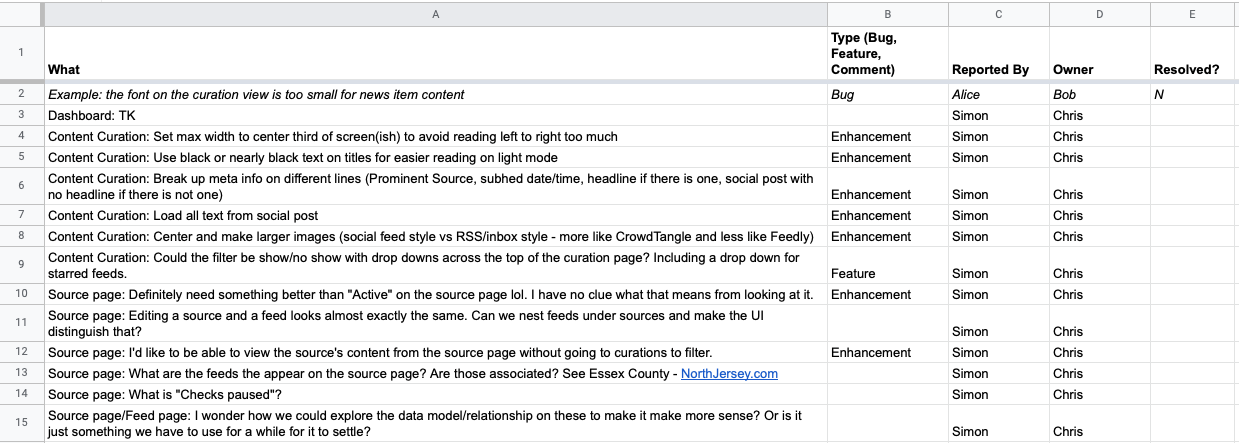
The first round of feedback that came in was a mix of big picture refresh questions about the data model, smaller aesthetic suggestions, and enhancements/requests around the content curation view:
Some of those items were easily addressed through minor refinements, but others were more substantial, so on April 20th, Simon and I did a phone call to talk through them. Here are my rough notes from that conversation:
In general we’re going in the right direction, excited to get the “design quirks” ironed out
The responsive and mobile-friendly nature of the tool is good
Possibility of bringing in a collaborator/consultant Simon has worked with for additional UI feedback later on
Conversation about terminology, re-clarifying differences and relationships between Sources and Feeds, and how those will ultimately be managed as the tool expands.
Filtering options for the Content Curation view could expand forever, so need to focus on making sure the default view is as helpful as possible to the daily workflow of the news producer
Need to switch from notion of “starred” Feeds to a more general way to tag Sources, including a tag like “Top” or “Favorite” that might be selected by default.
Would be helpful to be able to quick-add sources from the feed edit screen
Following the call and the subsequent updates to the feedback spreadsheet to reflect our conversation, the plan was for me to deliver the refined version of the tool back to Simon and team by the end of that same week (so, April 22nd) so they could continue their testing.
You can see the ongoing work on the Laravel News Harvester package based on this feedback and other requests by viewing the commit history on GitHub. Again, this package and tool is now available for any other organization to use, benefit from and contribute to.
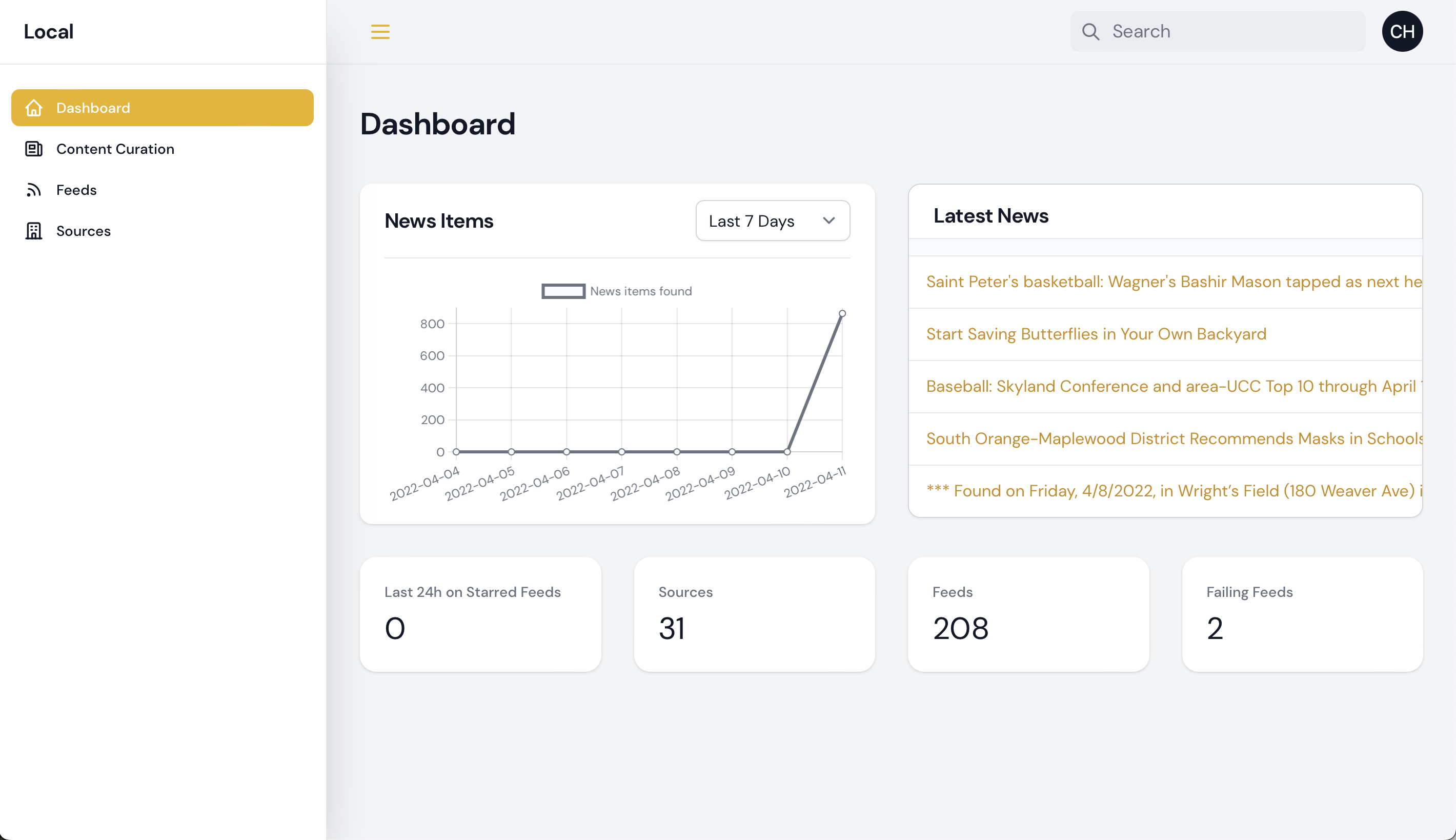
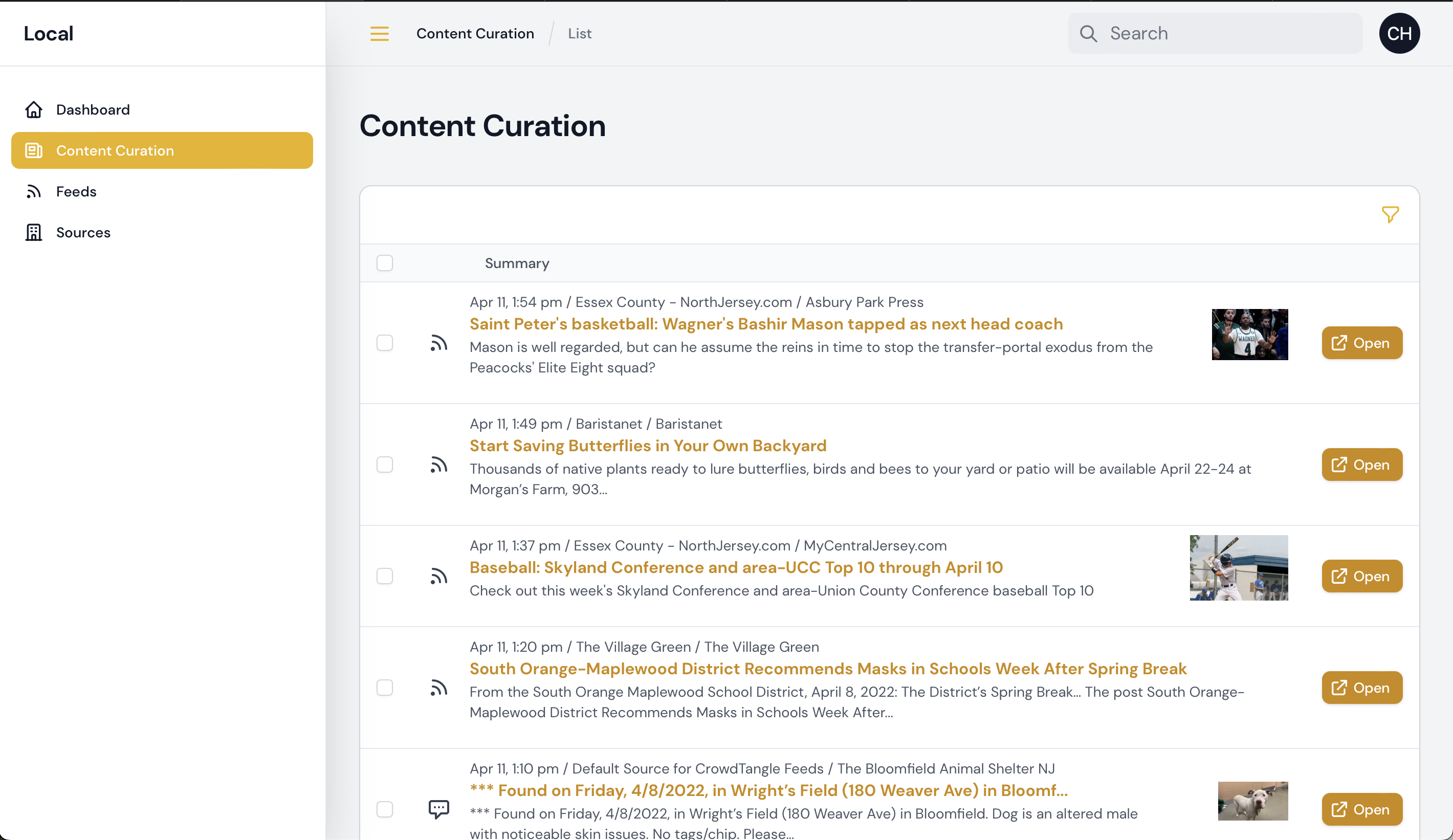
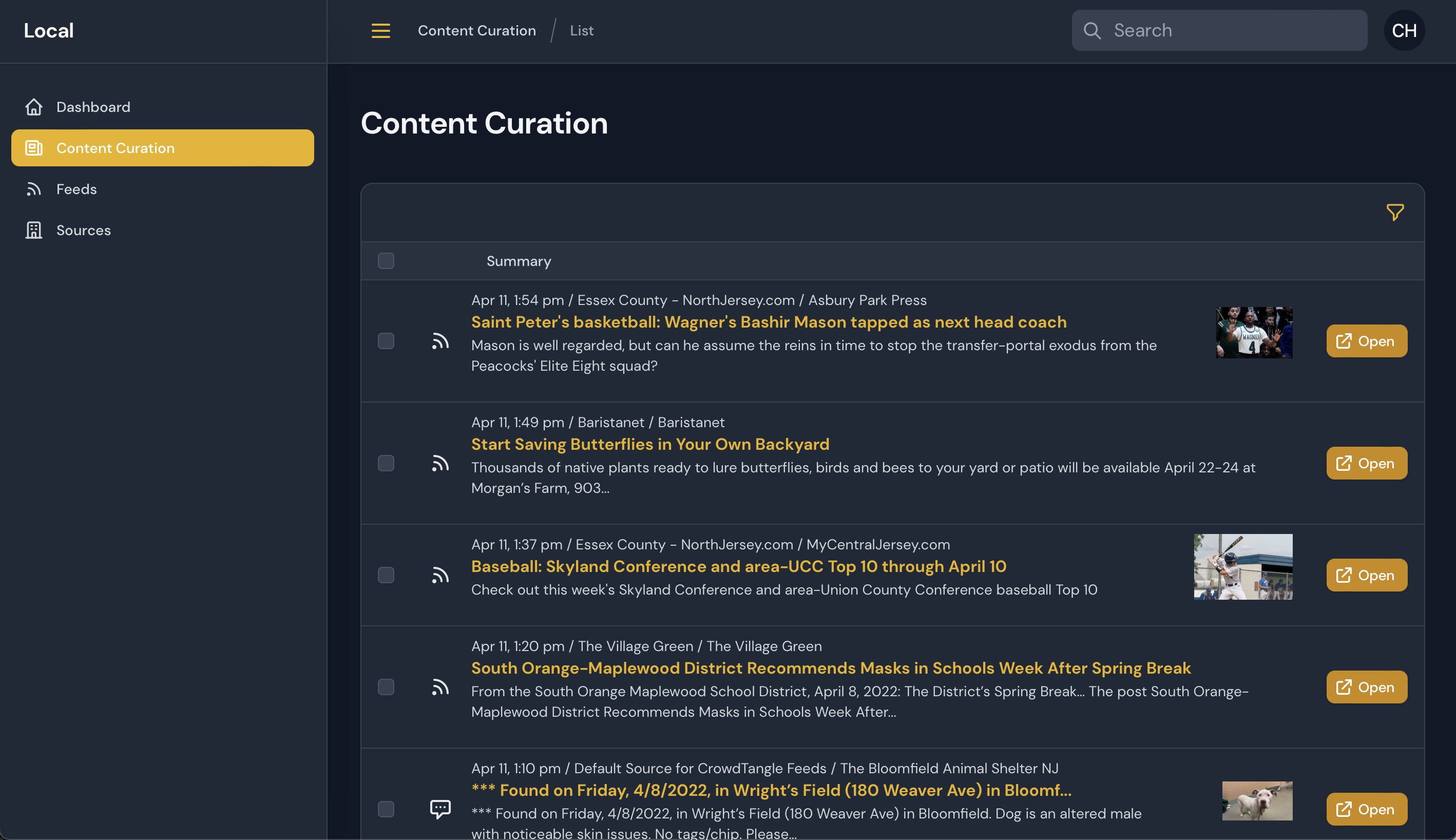
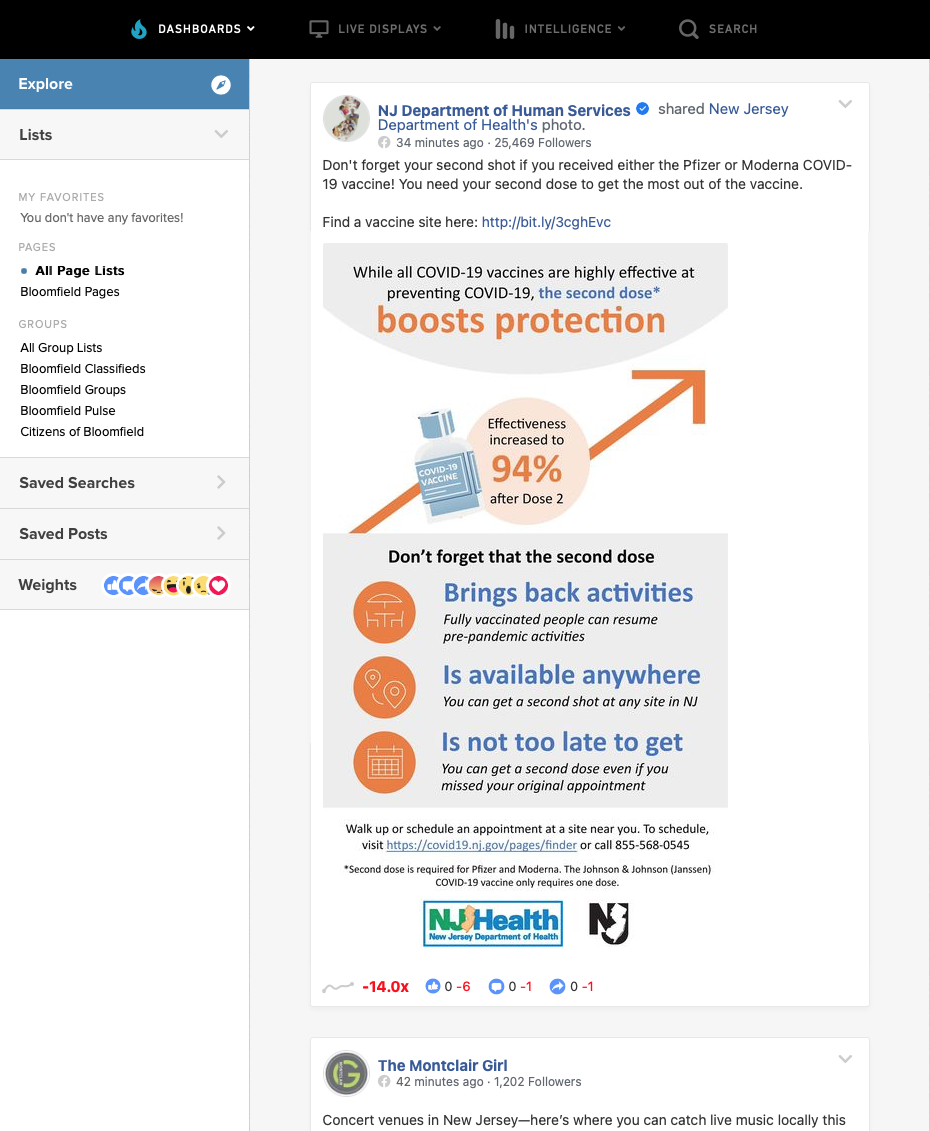
Today I delivered to Simon and team the first “beta” version of the new tool. Here’s what it looks like, actively monitoring various RSS and Facebook feeds:
While working on the software code I’ve been keeping a list of changes over time, using the software tracking tool git. I thought I’d share that “changelog” here for posterity, as I won’t include it in the initial “release” of the software package for public consumption.
These entries may not be entirely clear as they’re usually shorthand summaries of the work that’s just been done. Sometimes they represent just a line or two of code changes, and sometimes they represent many new functions and features coming in all at once. But here they are (in reverse chronological order as of today) in case they’re useful:
2022-04-09
Add but don’t use a welcome widget, need to work out width issues
News item trend chart
Latest news dashboard widget and starred feed activity count
Remove default account widget
Initial setup for dashboard stat widgets
Reorder sidebar for daily workflow
Enable dark mode and collapsible sidebar on desktop
Add Filament config to our package’s published configs for simplicity
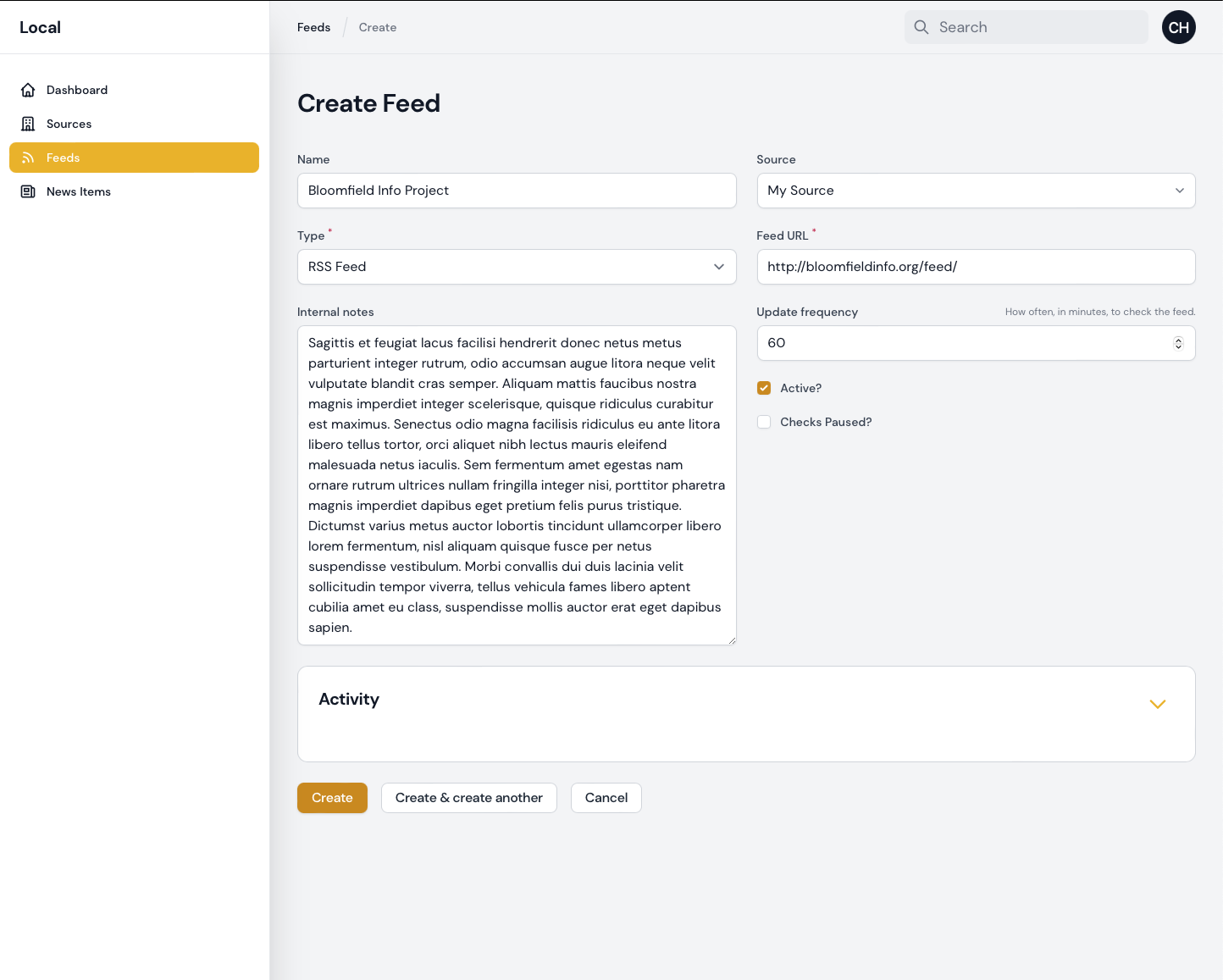
Don’t show activity section in create feed form
Disable manual creation of news items
Specify feed check freq when importing, better docs for import/export
Default to only last 7 days of news, show more records per page
Make news items globally searchable with useful result formatting
Create artisan command, job and schedule for checking bulk feeds
Make it look better on smaller devices
Align image center within container
WIP: news item media display in curation view
Support different title generation methods, move fetch history timeframe to config
Allow for apparently ridiculously long article URLs
Include parent methods in configuring and booted so Filament can load Livewire
2022-04-08
Refactor base class structure for better reusability of last check/update functions
Docs
Docs and clarifications
2022-04-07
Icon update for FB items until we can get a real one in there
Include feed names in curation view
Basic FB post fetching is working
WIP: adding bulk feed handling
2022-04-06
Start adding some better documentation in README and config
Set up package command scheduling
Add console command to refresh Crowdtangle feeds
2022-04-04
Action to refresh/create feeds from Facebook Pages and Groups
Basic setup for Crowdtangle API access
2022-04-03
Basic news item index tests
Add livewire test to check Source creation through Filament
Ridiculous scaffolding to support authenticated users when testing Filament views
Load Filament and base laravel migrations so we can test Filament
Maybe help testbench with package discovery
Add example app key to phpunit for local testing
Include Livewire service provider so tests will pass
Included deleted feeds and sources for purposes of relationship fetch
Visually indicate that feeds are failing in the table
Have content curation record URLs go to the article in a new window
Expand length of media_url field to accomodate ridiculous image URLs
One of the requirements for the tool I’m building is to integrate with the CrowdTangle API to pull the latest posts from Facebook groups and pages for consideration to be included in Bloomfield’s Daily Bulletin.
Since Facebook does not provide API access to Facebook page or group content unless you are an owner/administrator of those pages and groups, CrowdTangle is, as far as I’m aware, the one and only official tool available to journalists and researchers who want to have programmatic access to updates from a large number of Facebook groups and pages.
Here’s what the dashboard looks like on the CrowdTangle site:
CrowdTangle has some good documentation for their API but I was not able to find much in the way of tooling or libraries for interacting with their API, even though it’s used widely by journalism organizations.
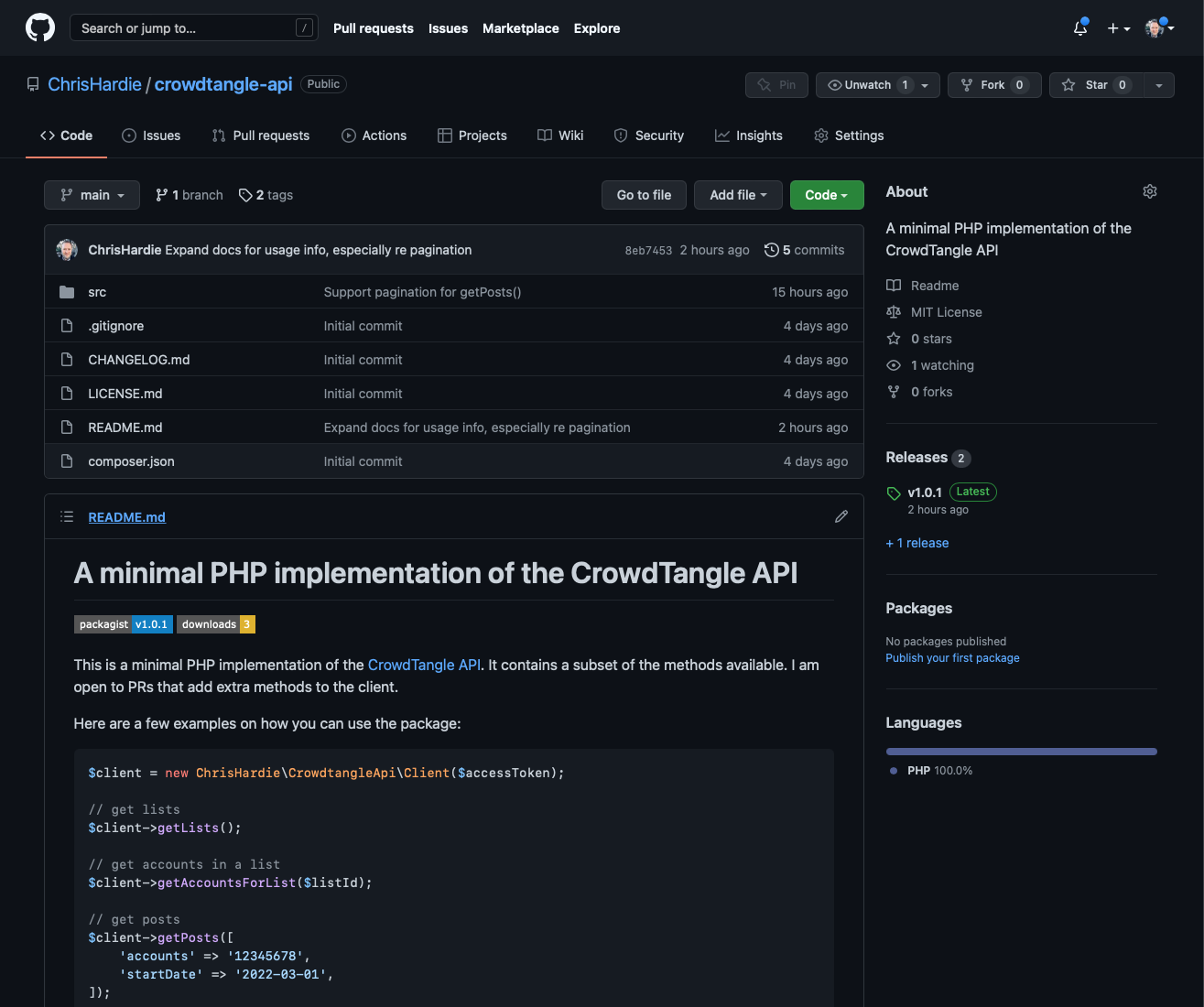
Since I would need to build that kind of library for this capstone project anyway, I decided to do it in a way that could benefit other journalism organizations, and created it as an open source package that is now available on GitHub:
So now, anyone building an application in PHP that needs to integrate with CrowdTangle will have a head start that hopefully helps them get up and running much faster.
I let the Facebook/Meta/CrowdTangle folks know about it and they are currently testing it out for inclusion in their documentation. I also shared about it on my personal technology blog. And of course, I’m now making use of it in the Bloomfield web application.
Continue to develop the software application and work toward delivering a first version for testing by the Bloomfield folks next week.
Based on feedback and real-world testing, make refinements and re-deliver, repeating that cycle as needed.
Problems
The Bloomfield team has had some challenges locating and contacting additional stakeholders for me to interview (at least one representative reader of the Daily Bulletin, and one person who has provided financial support to the project). Still hoping and expecting to be able to complete these conversations soon.
Some concerns have come up in the wider tech and journalism communities about the long-term plans for CrowdTangle, a tool that the Bloomfield team uses heavily in their news harvest and that I am working on integrating into the software. There’s nothing actionable on this for the moment but it may change some aspects of how that integration ends up working.
Some challenges lining up schedules between the Bloomfield team’s projects/priorities/travel as well as losing some time due to some family illness on my end mean that I’m again not quite where I want to be in terms of schedule. To compensate, I’ll be spending some of April beginning my write-up and summaries (originally intended for May).
Now that I’m on my way in actually building the first version of the news harvest tool, I thought I’d say a bit about the software development process itself.
We’ve decided to build this web application using the Laravel application framework. Created in 2011, Laravel is written in the PHP programming language and used around the world for building everything from personal websites to SaaS applications to mission-critical business tools. It’s also a very stable framework with a large community of open source contributors and developers for hire, which means that finding people to add and maintain Laravel functionality is relatively easy compared to more specialized or proprietary tools. All of these things combined set it up as a good choice for the Bloomfield folks to build on in the long term.
In February, I wrote on my personal technology blog about the tools I use for Laravel-based projects, and the list remains applicable here:
To organize and track the work itself, since I’m the only developer working on the project, I’m mostly referring to the mockups, data model and then using a simple text file broken down into “DONE,” “TODO,” and “LATER” sections:
In this post I’ll share the finalized wireframes that I’ve developed for my initial capstone project work and that also illustrate the possibilities for future phases of development and software tooling. As expected, these wireframes reflect several rounds of wireframe creation, delivery, design discussions, decision-making, wireframe refinement, and then repeating that process.
Here are the wireframes for the capstone project scope:
Over the last few weeks I’ve been working with Simon to talk through and refine some wireframe mockups of how the new application/tool could work. I’ll share about those separately soon, but one interesting and important conversation that came out of this process is about how the Bloomfield team does their review of content that comes in through the existing news harvest process, and how that should be reflected in a new workflow and tool.
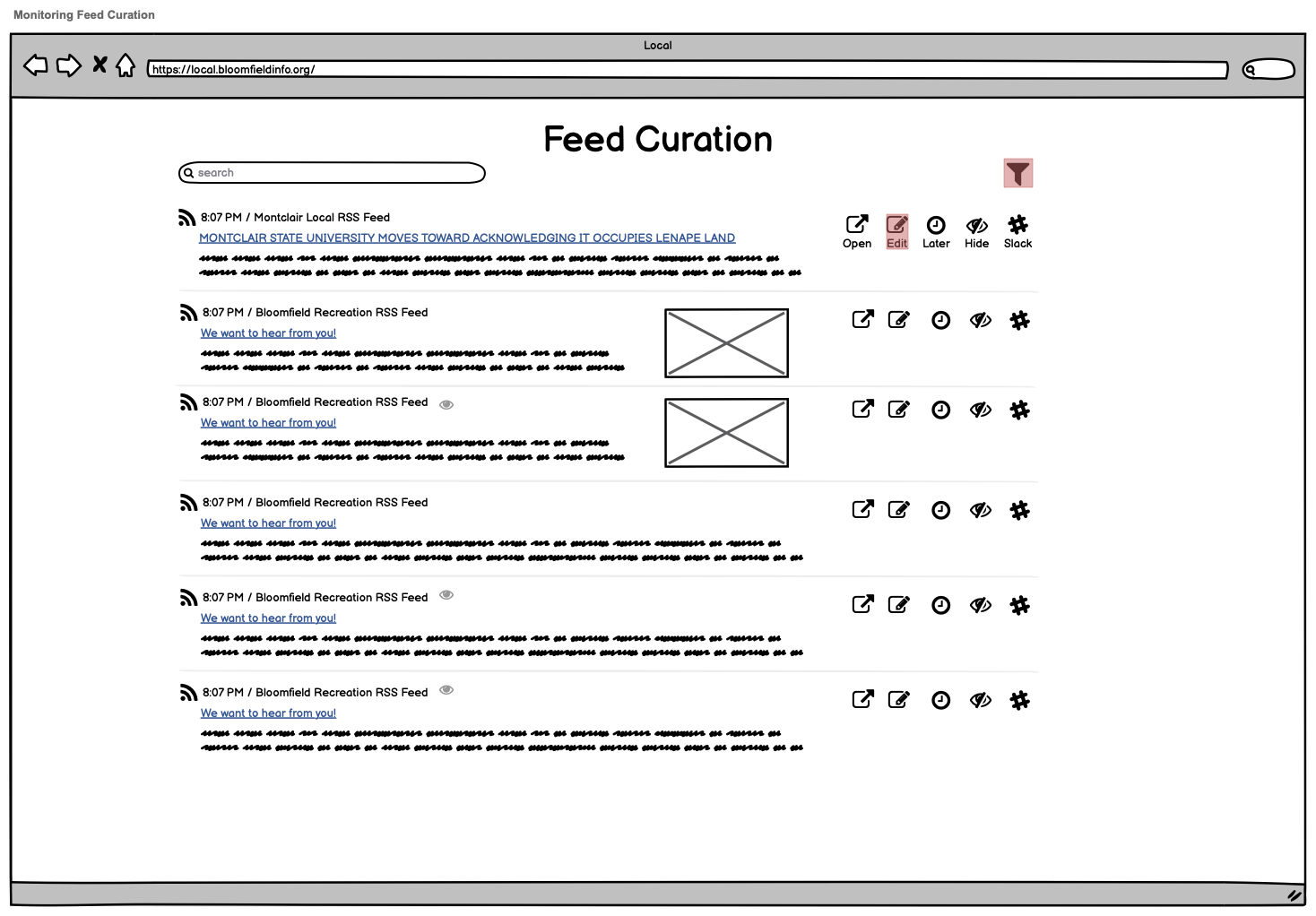
I made an assumption in the process of developing the mockups that it could work well to see a content item’s original headline in an administrative “curation” view and then, for purposes of rewriting the headline for the project’s Daily Bulletin, either open a new window to view the article/content in its original content, or just go straight to editing the headline in a pop-up modal within the tool.
Here’s one of the original mockups from March 1st showing the proposed feed curation view:
You can see the “Open” and “Edit” buttons for those two proposed ways of working with the content. Open would open a new browser window to the original article, and Edit would do something like this: